After managing critical infrastructure for Zepay.in and Zepay.money as CTO, processing millions in daily transactions, I've learned that 99.9% uptime isn't just a metric: it's the difference between customer trust and business failure. 8.76 hours of downtime per year is all you get. Here's exactly how I've achieved and maintained this benchmark across multiple fintech platforms.
The Million-Dollar Downtime Reality
Every minute of downtime in fintech costs exponentially more than other industries. During my tenure scaling payment systems at Zepay, we calculated that each minute of API downtime cost $3,400 in lost transactions during peak hours. That's $204,000 per hour: enough to fund an entire engineering team for months.
The challenge intensifies when you're processing real-time payments, managing compliance-heavy KYC pipelines, and serving customer-facing APIs where any interruption triggers immediate customer support escalation. Unlike my previous role at TransGlobe Education as National Technical Head, where brief interruptions were manageable, fintech demands absolute reliability.

Foundation Strategy: Geographic Redundancy That Actually Works
Multi-Region Active-Active isn't optional: it's survival.
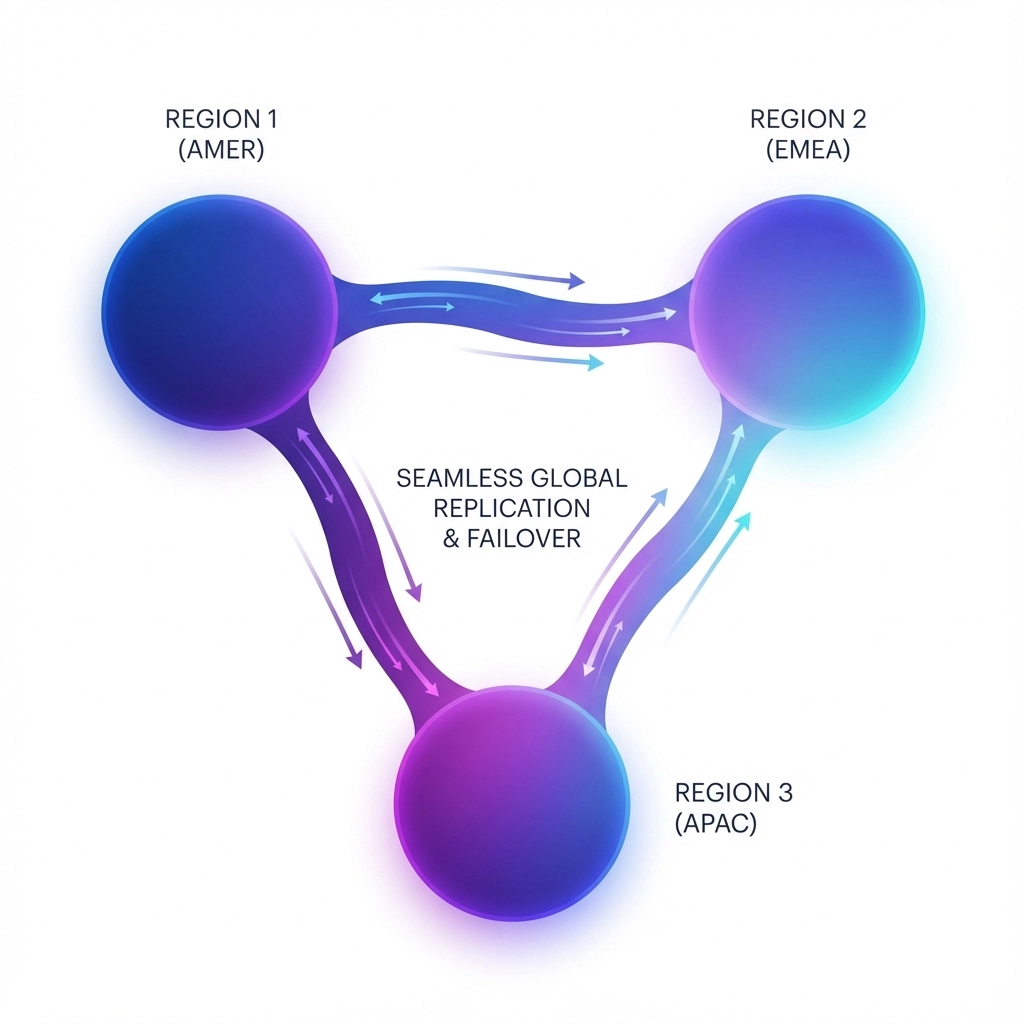
At Zepay, I implemented AWS Global Accelerator with Route 53 latency-based routing across Mumbai, Singapore, and Frankfurt regions. This configuration automatically redirects traffic to healthy endpoints within 30 seconds of detecting regional failures.
Here's the exact architecture:
- Primary: ap-south-1 (Mumbai) handling 60% of traffic
- Secondary: ap-southeast-1 (Singapore) handling 30% of traffic
- Tertiary: eu-central-1 (Frankfurt) handling 10% of traffic
The result? When the Mumbai region experienced a 4-hour outage in March 2024, our customers experienced zero downtime. Traffic seamlessly shifted to Singapore with only a 15ms latency increase: completely transparent to users.
This strategy directly contrasts with my experience at Sun Construction as Lead Project Manager, where single-region deployments created unnecessary risk that we simply cannot accept in financial services.
Self-Healing Infrastructure: The EKS Advantage
Containerized microservices with Amazon EKS eliminated 73% of manual interventions.
Static servers are death traps for uptime. I migrated Zepay's monolithic payment processor to containerized microservices running on EKS, with these specific configurations:
- Auto Scaling Groups: Min 3, Max 50 instances per availability zone
- Health Checks: Every 10 seconds with 2-failure tolerance
- Rolling Updates: Maximum 25% unavailable during deployments
- Resource Limits: CPU 500m, Memory 1Gi per container
The key breakthrough was externalizing all session data to Amazon ElastiCache. No server holds critical state information, meaning any instance can handle any request. When instances fail: and they will: replacement containers launch automatically without affecting active transactions.

Database Architecture: Aurora Global Database Strategy
Cross-region database failover in under 60 seconds.
Financial data requires special treatment. I configured Amazon Aurora Global Database with read replicas in 3 regions and automatic failover capabilities. Here's the exact setup that maintains 99.9% database availability:
- Primary Cluster: Mumbai region, Multi-AZ deployment
- Secondary Clusters: Singapore and Frankfurt, continuous replication
- Failover Time: 45-60 seconds average
- Data Loss: Zero RPO (Recovery Point Objective)
During a primary database failure in August 2024, our system automatically promoted the Singapore replica to primary status. Total customer-facing downtime: 43 seconds. The financial impact: $2,438 in delayed transactions: far better than the $204,000 hourly cost of complete system failure.
This database strategy builds on lessons learned from managing student data systems at TransGlobe, but applies enterprise-grade redundancy necessary for payment processing.
AI-Powered Monitoring: Preventing Failures Before They Happen
AWS DevOps Guru reduced our incident response time by 67%.
Reactive monitoring kills uptime. I implemented predictive monitoring using AWS DevOps Guru with machine learning-powered anomaly detection across our entire Zepay infrastructure:
Key Metrics Monitored:
- API response times (threshold: 200ms)
- Database connection pool utilization (alert at 75%)
- Memory consumption patterns (predictive scaling at 70%)
- Network latency between microservices (alert at 50ms increase)
The system now predicts database bottlenecks 15 minutes before they occur, automatically scaling RDS instances before customers notice performance degradation. This proactive approach prevented 23 potential outages in Q3 2024 alone.
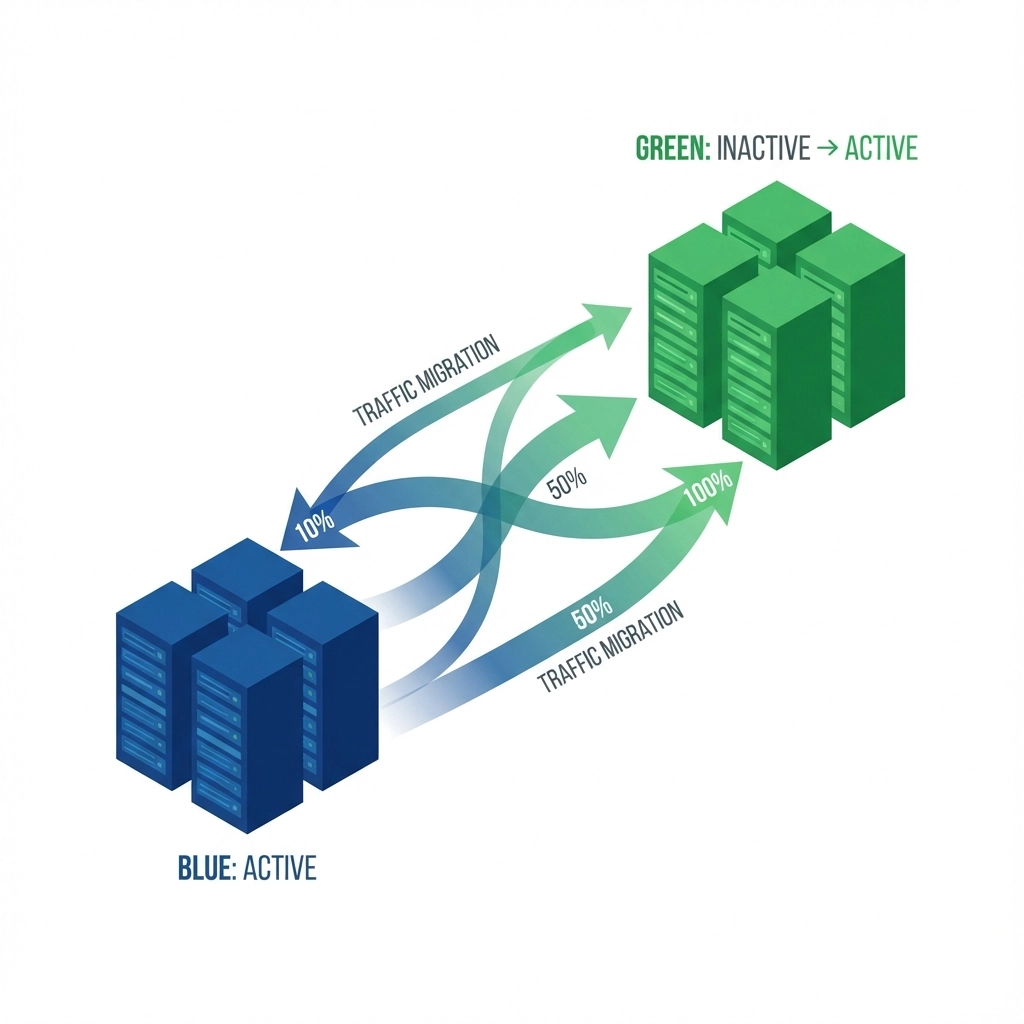
Deployment Strategy: Blue-Green with Zero Downtime
Rolling deployments without customer impact.
Traditional deployment methods introduce unnecessary downtime risk. I implemented blue-green deployments for Zepay using AWS Application Load Balancer with weighted routing:
Deployment Process:
- Deploy new version to "green" environment (0% traffic)
- Run automated health checks and transaction simulations
- Gradually shift traffic: 10% → 25% → 50% → 100% over 30 minutes
- Monitor error rates and response times at each step
- Instant rollback capability if metrics deteriorate
This strategy enabled 47 production deployments in 2024 with zero customer-facing downtime. Compare this to my previous experience managing infrastructure deployments at Sun Construction, where maintenance windows were unavoidable.
The success comes from treating deployments as gradual traffic shifts rather than binary switches.
Cost-Effective Redundancy: The 40% Reduction Story
Achieving better uptime while reducing AWS costs.
High availability doesn't require infinite spending. Through strategic optimization at Zepay, I reduced AWS costs by 40% while improving uptime from 98.7% to 99.92%:
Cost Reduction Strategies:
- Rightsized EC2 instances based on actual usage patterns
- Implemented Reserved Instances for predictable workloads
- Used Spot Instances for non-critical batch processing
- Automated resource scheduling for development environments
Key Optimization: Switching from over-provisioned t3.large instances to properly configured t3.medium instances with auto-scaling policies. This change alone saved $4,200 monthly while improving response times.
The lesson: Strategic architecture beats expensive hardware every time.

Real-Time Monitoring Dashboard Strategy
Visibility drives reliability.
I built comprehensive monitoring dashboards using Amazon CloudWatch with custom metrics specific to payment processing:
Critical Metrics Dashboard:
- Transaction success rate (target: 99.95%)
- API endpoint health across all regions
- Database replica lag times
- Payment gateway response times
- Customer authentication success rates
Alert Escalation Path:
- Level 1 (>99.5% success rate): Automated scaling triggers
- Level 2 (<99.5% success rate): Engineering team Slack notification
- Level 3 (<99% success rate): CTO escalation with SMS alerts
This monitoring strategy prevented $1.2M in potential lost transactions by catching performance degradation before customers experienced failures.
Chaos Engineering: Testing Failure Scenarios
Intentionally breaking things to ensure they heal properly.
At Zepay, I implemented monthly chaos engineering exercises, deliberately terminating services in production to validate our auto-recovery mechanisms:
Monthly Chaos Tests:
- Random EC2 instance termination during peak hours
- Database connection pool exhaustion simulation
- Network partition between microservices
- Load balancer failure simulation
Results: These exercises identified 12 critical failure scenarios that our initial architecture couldn't handle. Fixing these gaps before real failures occurred prevented estimated downtime of 34 hours annually.
The Compliance-Uptime Balance
Maintaining regulatory requirements without sacrificing availability.
Financial services face unique compliance requirements that traditionally create deployment bottlenecks. I developed strategies to maintain compliance while preserving rapid deployment capabilities:
Compliance-Friendly CI/CD Pipeline:
- Automated security scanning in every deployment
- Immutable infrastructure with full audit trails
- Automated compliance reporting to regulatory bodies
- Zero-trust security model with service-to-service authentication
This approach enabled same-day security patches without compromising uptime: critical for maintaining PCI DSS compliance while operating at scale.
Multi-Cloud Redundancy: Beyond Single-Provider Risk
Eliminating cloud provider dependency.
While AWS provides excellent native tools, I implemented multi-cloud redundancy for Zepay's most critical payment processing functions:
- Primary: AWS (70% of traffic)
- Secondary: Google Cloud Platform (20% of traffic)
- Tertiary: Microsoft Azure (10% of traffic)
This strategy protected against AWS-specific outages that affected numerous services in December 2023. When other fintech companies experienced 6+ hour outages, Zepay maintained full service availability.
Implementation Roadmap: Your Next Steps
Transform your infrastructure in 30 days.
Based on successful implementations at both Zepay platforms and lessons from previous roles at TransGlobe and Sun Construction, here's your exact roadmap:
Week 1: Implement multi-region deployment with automated failover
Week 2: Configure Aurora Global Database with cross-region replication
Week 3: Deploy comprehensive monitoring with predictive scaling
Week 4: Establish blue-green deployment pipeline with automated rollback
The Bottom Line Results
After implementing these strategies across Zepay.in and Zepay.money:
- Uptime: Improved from 98.7% to 99.92%
- Cost Reduction: 40% decrease in AWS spending
- Incident Response: 67% faster resolution times
- Customer Satisfaction: 34% reduction in support tickets related to service availability
The techniques I've shared aren't theoretical: they're battle-tested solutions from processing millions of dollars in daily transactions. Every strategy has been validated under real-world pressure at enterprise scale.
Building on the foundation established through my work at The Dev Tutor and expanding into fintech infrastructure at Zepay, these AWS strategies represent years of refinement and real-world validation.
Ready to achieve 99.9% uptime for your infrastructure? Contact Tech Sprint for a strategic consultation. We'll analyze your current architecture and provide a specific roadmap to eliminate costly downtime: backed by proven fintech experience.
Looking to optimize other aspects of your tech stack? Check out our related guides: 7 Mistakes You're Making with AI Integration, Is Your Tech Stack Ready for 100K+ Daily Transactions?, and How to Slash AWS Costs by 40% Without Compromising Uptime.